推荐书籍:
Java 基础
从当前所在路径加载类SET ClASSPATH=.
PATH:是操作系统提供的路径配置,定义所有可执行程序的路径
CLASSPATH:是由 JRE 提供的,用于定义 Java 程序解释时类加载路径CLASSPATH=路径的命令形式来进行定义;
Java 1.9 之后才有的Jshell
int的取值范围为-2147483648 到 2147483647
大写字母范围:A(65)~Z(90)
小写字母范围:a(97)~z(122)
数值范围:‘0’(48)~'9’(57)
this关键字
this():调用无参的构造函数
this(name):调用参数为 name 的构造函数
this(…):必须放在首行
Static 属性由类名直接调用
static 方法只允许调用 static 属性或 static 方法
非 static 方法允许调用 static 属性或 static 方法
static 的定义的方法或属性都不是代码编写之初所需要考虑的内容,只有在回避实例化对象描述公共属性的情况下才会考虑 static 定义的属性或者是方法
静态代码块最先执行,而且只会执行一次,用于对静态属性的初始化,构造块会优于构造方法先执行
数组
int数组初始化默认为 0
必须实例化数组才能使用数组下标
foreach循环可以避免使用下标,
foreach遍历二维数组
返回数组的方法
将数组封装成一个组件
数组快速排序
数组逆序
数组相关的类库
数组排序可以这样写java.util.Arrays.sort(data);
系统自带的数组拷贝System.arraycopy(dataA,5,dataB,5,3);是将数组dataA中从索引为 5,长度为 3 的一段数组复制到dataB中索引位置为 5 的地方,并替换掉相应长度
可变参数
在方法参数列表中...表示可变参数
可变参数的作用在于,在以后进行一些程序设计或者开发者调用的时候,利用此种形式可以避免数组的传递操作
对象数组定义格式如下:
- 动态初始化:类 对象数组名称[]=new 类[长度],每一个元素的内容都是 null
- 静态初始化:类 对象数组名称[]=new 类[]{实例化对象,实例化对象,实例化对象…}
String
java 源代码目录:C:\Program Files (x86)\Java\jdk-9\lib\src.zip
JDK 1.8 及以前的 String 支持类
JDK 1.9 的 String 支持类
JDK 1.8 及以前 String 类保存的是字符数组
JDK 1.9 及以后 String 类保存的是字节数组
String 对象的比较
直接为字符串赋值会是字符串变量指向字符串池中的内存地址
new String()会开辟新的内存
将所有小写字母转换成大写
先将字符串转换成字符数组,然后每个字符的编码-32
判断是否全为数字
先将字符串转换成字符数组,if (result[i] < '0' || result[i] > '9')
然后挨个判断每个字符
字符串的比较
str.equals(str1)区分大小写比较
str.equalsIgnoreCase(str1)不区分大小写比较
str.compareTo(str1)字符串的大小的比较
str.compareToIgnoreCase(str1)忽略大小写的字符串大小比较
字符串的查找
str.contains("hello")判断字符串中是否含有 hello
str.indexOf("Java")查询 Java 是否存在于 str 中,存在返回首字母索引位置,不存在返回-1
str.lastIndexOf("Java")从后向前查询
str2.endsWith("com")判断是否以 com 结尾
str2.startsWith("www")判断是否以 www 开头
字符串的替换
str.replaceAll("Java", "Python")将全部的 Java 替换成 Python
str.replaceFirst("Java", "Python")将第一个 Java 替换成 Python
字符串的拆分
str.split(" ")以空格全部拆分,返回字符串数组
str.split(" ",2)以空格拆分成 2 个,返回字符串数组
str1.split("\\.")拆不开的情况要用”\“进行转义
字符串的截取
str.substring(startIndex,endIndex)截取str从startIndex到endIndex的字符串片段
字符串的格式化
format 是一个静态方法,直接通过String 类调用String.format("姓名:%s,年龄:%d,分数:%5.2f",name,age,score)
其他字符串相关的方法
str.concat(str2)字符串的连接
str.isEmpty()判断字符串内容是否为空
str.trim()去掉字符串中所有空格
str.toUpperCase()全部转换成大写
(str.toLowerCase()全部转换成小写
面向对象
继承
public class object.Student extends object.PersonStudent 类继承 Person 所有共有的属性和方法
子类被实例化时先调用父类的构造方法
super(...)必须放在首行,this(...)也必须放在首行,所以两者不可同时出现
多层继承
理论上层数最多不能超过三层
- 父类的私有方法不存在覆写
- 子类调用有父类覆写的方法要加 super
| Overloading | Override |
|---|---|
| 重载 | 覆写 |
| 方法名称相同,参数的类型及个数不同 | 方法名称,参数类型及个数,返回值相同 |
| 没有权限限制 | 被覆写方法不能拥有更严格的控制权限 |
| 发生在一个类中 | 发生在继承关系类中 |
在程序类中使用 this 表示先从本类查找所需要的的属性或方法,如果本类中不存在则查找父类定义,如果使用 super 则不查找子类,直接查找父类
fanal 代表不能被覆写的方法,常量
Annotation 注解
@Override准确覆写
@Deprecated 代表过时的类或方法
@SuppressWarnings 压制警告
多态
向上转型base f = new son()可以调用父类的方法和子类中重写父类的方法
向下转型son1 s=(son)f不安全
instanceof
instanceof为了保证向下转型的正确性,用于在转型之前进行判断,判断某个实例是否是某个类的对象
Object 类
Object 类是所有类型的父类,所以 Object 类可以接收所有子类的对象
toString()是 Object 自带的方法,所有继承类都可以使用
- 对象比较 equals()
- 判断对象是否为 null
- 判断是不是同一地址
- 判断 obj 是否转换为 person
- 判断内容是否相同
抽象类
抽象方法所在的类必须为抽象类,抽象类必须用abstract关键字来定义
抽象类就是在普通类上追加了抽象方法
抽象类是无法被实例化的
- 抽象类必须提供子类
- 抽象类的子类(非抽象类)一定要覆写抽象类中的全部抽象方法
- 抽象类的对象实例化可以通过子类向上转型的方式完成
抽象类自己无法直接实例化
final不允许有子类,abstract必须有子类
抽象类中可以使用普通方法调用抽象方法
包装类
Int temp = new Int(10);装箱,将基本数据类型保存在包装类中
int x = temp.intValue();拆箱,从包装类中获取基本数据类型
- 对象型的包装类,
Boolen,Character - 数值型的包装类,
Byte,Short,Integer,Long,Float,Double
基本的装箱与拆箱操作
jdk1.5 之后可以实现自动装箱与拆箱操作,包装类可以直接参与数学运算
接口
接口的组成以抽象方法和全局常量为主,使用关键字interface定义,接口的名称通常首字母加上I
- 接口需要被子类实现,关键字
implements,一个子类可以实现多个接口 - 子类(非抽象类)必须覆写接口中的全部抽象方法
- 接口对象可以通过子类对象的向上转型实例化
接口的主要目的是一个子类可以实现多个接口
接口不允许继承父类
Object 类对象可以接收所有的数据类型,包括基本数据类型,类对象,接口对象,数组…
方法不写访问权限也是
public,不是default
接口可以通过extends集成多个父接口
接口的使用:
- 进行标准设置
- 表示一种操作的能力
- 暴露远程方法视图
JDK1.8 之前,在进行设计时,一般子类不直接继承接口,中间加一个过渡抽象类
接口的方法加上public default代表普通方法
设计模式
代理设计模式
一个接口提供两个子类,其中一个是真实业务操作类,另一个是代理业务操作类
接口与抽象类的比较
| 接口 | 抽象类 |
|---|---|
| interface 接口名称{} | abstract class 抽象类名称{} |
| 抽象方法,全局常量,普通方法,静态方法 | 构造,普通方法,静态方法,全局变量,成员 |
| 只有 public 权限 | 可以使用各类权限 |
子类通过implements关键字可以继承多个接口 |
子类通过extends关键字继承一个抽象类 |
| 接口不允许结成抽象类,可以继承多个父接口 | 抽象类可以实现若干个接口 |
使用时的共同点
- 抽象类或接口必须定义子类
- 子类必须覆写抽象类或接口的全部抽象方法
- 通过子类的向上转型实现抽象类或接口的对象实例化
单例设计
懒汉式
在第一次使用时进行实例化处理
饿汉式
在系统加载类时,实例化对象
多例设计
单例设计是指只保留一个实例化对象,多例设计是指保留多个实例化对象
单例设计和多例设计的本质是相同的,一定都会在内部提供有static方法以返回实例化对象。都要进行构造方法私有化
泛型
基本数据类型 → 包装类型 →Object类
向上转型成Object类,容易出现ClassCastException异常
- 泛型之中只允许设置引用类型,如果要操作基本类型必须使用包装类
- 泛型对象实例化对象可以简化为
Point<Integer> p1=new Point<>();
通配符<?>可以使泛型对象在方法中不被改变
<T extends 类>:设置泛型的上限
<T super 类>:设置泛型的下限
泛型接口
子类实现泛型接口两种方式:
-
在子类之中继续设置泛型定义
-
子类实现父接口是直接定义泛型类型
泛型方法
泛型方法不一定出现在泛型类之中
工厂模式中使用泛型方法
包
同一个目录下不能有同名的程序文件,要创建不同的目录,不同的的目录就是不同的包
javac -d . hello.java
-d:表示要生成目录,目录为package定义的结构
.:表示从当前目录开始生成
类的名称:包.类名称
import util.Message;导入其他包的类
当导入的几个包中出现重名的类时,定义类要用完整的类名称Message msg=new util.Message();。
静态导入
import static util.Math.*;静态导入后可以直接使用util.Math中的方法
Jar
想用javac编译,然后用jar打包
jar -cvf "名称.jar" 文件夹
-c创建一个新的jar文件
-v得到一个详细输出
-f设置生成的Jar文件名称
系统常见包
java.lang包括 String,Number,Object 等
java.lang.reflect反射机制处理包
java.util工具类的定义,包括数据结构的定义
java.io进行输入与输出流操作的包
java.net网络程序开发的程序包
java.sql进行数据库编程的开发包
java.awt和java.swingJava 的图形界面开发包,awt 是重量级的组件,swing 是轻量级的组件
访问控制权限
面向对象的三个主要特点:封装,继承,多态
| 访问范围 | private | default | protected | public |
|---|---|---|---|---|
| 同一包中的同一类 | √ | √ | √ | √ |
| 同一包中的不同类 | √ | √ | √ | |
| 不同包的子类 | √ | √ | ||
| 不同包的所有类 | √ |
UML
UML 是统一的建模语言,本质是利用图形化的形式来实现程序类关系的描述
类图
类一般用三层结构来显示
| 类名称 |
|---|
| 属性 |
| 方法 |
抽象类一般用斜体表示,也可以加上abstract
属性的格式为访问权限 属性名称:属性类型
访问权限的表示符为 public(+),private(-),protected(#)
方法的格式为访问权限 方法名称():返回值结构
子类实现接口用"三角和虚线”,类的继承用"三角和实线”,由子类指向父类
时序图
时序图用于描述代码的执行流程
用例图
用例图用于描述程序的执行分配
枚举
枚举主要作用于定义有限个数对象的一种结构(多例设计),通过enum定义枚举类
遍历枚举
c.ordinal():c 在枚举类中的序号
c.name():c 的值
enum:是从 JDK1.5 之后提供的一个关键字,用来定义枚举类Enum:是一个抽象类,所有使用enum关键字定义的类,默认继承此类
异常
处理异常的三种组合:try...catch,try...catch...finally,try...finally
通过e.printStackTrace();获取完整的异常信息
异常处理流程
- 产生异常,自动产生异常的实例化对象
- 如果不处理异常,JVM 默认打印异常信息,然后退出程序
- 如果存在异常处理,异常实例化对象将会被
try语句捕获 catch匹配异常- 执行
finally
处理异常最大的类型是Throwable,有两个子类
Error:此时程序还未执行出现的错误,开发者无法处理Exception:程序中出现的异常
在多个异常处理的时候要将捕获范围大的异常放在捕获范围小的异常后面
通过throws抛出异常
throw手动抛出异常
throw和throws的区别
throw是在代码块中使用的,主要是手工对异常对象的抛出throws是在方法定义上使用的,表示将此方法中可能产生的异常明确告诉给调用处,由调用处进行处理
RuntimeException是Exception的子类
常见的RuntimeException: NullPointerException,ClassCastException,IndexOutOfBoundsException
内部类
内部类的优点是可以轻松地访问外部类的私有属性,缺陷是破坏了类的结构
内部类和外部类之间的操作不需要setter和getter,内部类实例化对象的格式外部类.内部类 内部类对象=new 外部类().new 内部类;
如果Inner类加上private属性,则Inner无法在外部进行使用
static的类和方法只能访问外部类的static的属性或方法.
static定义的内部类并不常用,static定义内部接口更常用
在方法中定义内部类
方法中的内部类既能访问方法中的参数,又能访问外部类的私有成员属性。对于方法中参数的访问是从 JDK1.8 开始支持的。
匿名内部类的使用
往往使用静态方法做一个内部的匿名内部类
匿名内部类只是一个没有名字的只能够使用一次的,并且结构固定的一个子类
函数式编程
从 JDK1.8 开始提供有Lambda表达式的支持
Lambda表达式使用时有一个重要的实现要求就是 SAM(Single Abstract Method)只有一个抽象方法,该接口被称为函数式接口
Lambda 表达式的三种格式:
- 没有参数:
()->{}; - 有参数:
(参数,参数)->{}; - 只有一条返回语句
(参数,参数)->语句;
对方法的引用
-
引用静态方法:
类名称::static 方法名称;IFunction<String, Integer> fun = String::valueOf; -
引用某个实例对象的方法:
实例化对象::普通方法;IFunction fun="hellojava"::toUpperCase; -
引用特定类型的方法:
特定类::普通方法;IFunction<String> fun=String::compareTo; -
引用构造方法:
类名称::newIFunction<Person> fun=Person::new;
在java.util.funtion包中可以直接使用函数式接口
-
功能性函数式接口
1 2Function<String,Boolean> fun="hellojava"::startsWith; System.out.println(fun.apply("hello")); -
消费型函数式接口:只能进行数据的处理,没有任何的返回
1 2Consumer<String> fun=System.out::println; fun.accept("HelloJava"); -
供给型函数式接口
1 2Supplier<String> fun="hellojava"::toUpperCase; System.out.println(fun.get()); -
断言型函数式接口
1 2Predicate<String> fun="hello"::equals; System.out.println(fun.test("hello"));
链表
由于数组的长度是固定的,所以要引入链表
链表节点的增加
- 判断增加的节点是否为空
- 判断根节点是否为空
- 添加节点
Link 类只负责数据的操作与根节点的处理而所有后续节点的处理全部都是有 Node 类负责。
获取链表元素的个数
-
在
ILink接口中增加size()方法 -
在
LinkImpl中重写size()方法 -
在
LinkImpl中增加私有属性count,然后在add(E e)加上this.count++;语句
判断链表是否为空
既可以判断根节点是否为空,也可以判断长度是否为 0
返回链表数据
-
在
ILink接口中追加public Object[] toArray();方法 -
在
LinkImpl中加上两个属性 -
在
Node中递归获取数据 -
在
LinkImpl中重写public Object[] toArray();方法
链表数据的返回是以数组的形式返回
根据索引获取数据
-
ILink加上public E get(int index); -
在
Node中定义public E getNode(int index) -
在
LinkImpl中重写public E get(int index)
修改指定索引的数据
- 在
ILink加上public void set(int index,E value); - 在
Node中定义public void setNode(int index,E value) - 在
LinkImpl中重写public void set(int index, E value)
判断指定数据是否存在
- 在
ILink加上public boolean contains(E data) - 在
Node中定义public boolean containsNode(E data) - 在
LinkImpl中重写public boolean contains(E data)
数据删除
- 在
ILink中加上public void remove(E data) - 在
LinkImpl中判断要删除的元素是否为根节点 - 如果不是根节点,在
Node中定义删除节点 - 在
LinkImpl中完善public void remove(E data)方法
数据清除
- 在
ILink中追加public void clean();方法 - 在
LinkImpl中重写public void clean()
AWT
- AWT 界面组件:包括窗口、对话框、基本组件、菜单组件。
- AWT 布局管理器:包括流式布局 FlowLayout、区域布局 BorderLayout、网格布局 GridLayout、卡片布局 CardLayout。
- AWT 事件处理:事件授权模型、事件类型,监听器和适配器的使用。
AWT 的组件包括两大类:Component 和 MenuComponent,即组件与菜单栏
类 java.awt.Component 是许多组件类的父类,Component 类中封装了组件通用的方法和属性,如图形的组件对象、大小、显示位置、前景色和背景色、边界、可见性等。
一般我们要生成一个窗口,通常是用 Window 的子类 Frame 来进行实例化,而不是直接用到 Window 类
Panel是一个容器,放在 Frame 组件内,可以用于包装一组组件。
idea 中中文乱码设置
VM option: -Dfile.encoding=GB18030
对话框Dialog
创建文本对话框FileDialog
基本组件
- 文本
Label - 按钮
Button - 复选框
Checkbox - 复选框组
CheckboxGroup - 下拉列表
Choice - 文本框
TextField - 文本区域
TextArea - 列表
List - 画布
CAnvas
菜单组件
- 菜单栏
MenuBar - 菜单
Menu - 菜单选项
MenuItem
AWT 布局管理器
Frame 是一个顶级窗口。Frame 的默认布局管理器为
BorderLayout。Panel 无法单独显示,必须添加到某个容器中。Panel 的默认布局管理器为 FlowLayout。
当把 Panel 作为一个组件添加到某个容器中后,该 Panel 仍然可以有自己的布局管理器。因此,可以利用 Panel 使得
BorderLayout中某个区域显示多个组件,达到设计复杂用户界面的目的。如果采用无布局管理器
setLayout(null),则必须使用setLocation()、setSize()、setBounds()等方法手工设置组件的大小和位置,此方法会导致平台相关,不鼓励使用。
流式布局 FlowLayout
FlowLayout 是 Panel、Applet 的默认布局管理器。其组件的放置规律是从上到下、从左到右进行放置,如果容器足够宽,第一个组件先添加到容器中第一行的最左边,后续的组件依次添加到上一个组件的右边,如果当前行已放置不下该组件,则放置到下一行的最左边。
FlowLayout(FlowLayout.RIGHT,20,40);:第一个参数表示组件的对齐方式,指组件在这一行中的位置是居中对齐、居右对齐还是居左对齐,第二个参数是组件之间的横向间隔,第三个参数是组件之间的纵向间隔,单位是像素。
区域布局 BorderLayout
BorderLayout 是 Window、Frame 和 Dialog 的默认布局管理器。BorderLayout 布局管理器把容器分成 5 个区域:North、South、East、West 和 Center,每个区域只能放置一个组件。
不一定所有的区域都有组件,如果四周的区域(West、East、North、South 区域)没有组件,则由 Center 区域去补充,但是如果 Center 区域没有组件,则保持空白
网格布局 GridLayout
GridLayout 使容器中各个组件呈网格状布局,平均占据容器的空间,创建该布局时需要指定网格的行数和列数,然后依次添加各个组件时,会按照先行后列的顺序依次添加。
卡片布局 CardLayout
CardLayout 卡片布局管理器能够帮助用户处理两个以至更多的成员共享同一显示空间,它把容器分成许多层,每层的显示空间占据整个容器的大小,但是每层只允许放置一个组件,当然每层都可以利用 Panel 来实现复杂的用户界面。
AWT 事件处理
使用授权处理模型进行事件处理的一般方法归纳如下。
-
对于某种类型的事件 XXXEvent,要想接收并处理这类事件,必须定义相应的事件监听器类,该类需要实现与该事件相对应的接口 XXXListener。
-
事件源实例化以后,必须进行授权,注册该类事件的监听器,使用 addXXXListener(XXXListener )方法来注册监听器。
AWT 事件共有 10 类,可以归为两大类:低级事件和高级事件。
低级事件是指基于组件和容器的事件,当一个组件上发生事件,如:鼠标的进入、单击、拖放等,或组件的窗口开关等,触发了组件事件。
高级事件是基于语义的事件,它可以不和特定的动作相关联,而依赖于触发此事件的类,如在 TextField 中按 Enter 键会触发 ActionEvent 事件,滑动滚动条会触发 AdjustmentEvent 事件,或是选中项目列表的某一条就会触发 ItemEvent 事件。
事件监听器
每类事件都有对应的事件监听器,监听器是接口,根据动作来定义方法
使用事件监听器:实现监听器接口、使用内部类和匿名类。
使用事件适配器。
多媒体处理
- 图像处理——java.awt.image
- 二维图像绘制——Java2D。
- 音频录制与播放——JavaSound。
- 视频拍照与播放——JMF。
正则表达式
基本语法
- 八进制表示的字符,以
\0开头,后跟 1 ~ 3 位数字 - 十六进制表示的字符,以
\x开头,后跟两位字符 - Unicode 编号表示的字符,以
\u开头,后跟 4 位字符 - 点号字符
.是一个元字符,默认模式下,它匹配除了换行符以外的任意字符 - 以
(? s)开头,s 表示 single line,即单行匹配模式 - 为方便表示连续的多个字符,字符组中可以使用连字符’-’
- 字符组支持排除的概念,在
[后紧跟一个字符^,只有在字符组的开头才是元字符,如果不在开头,就是普通字符,匹配它自身 \d: d 表示 digit,匹配一个数字字符\w: w 表示 word,匹配一个单词字符\s: s 表示 space,匹配一个空白字符\D:匹配一个非数字字符\W:匹配一个非单词字符\S:匹配一个非空白字符
量词指的是指定出现次数的元字符:
+:表示前面字符的一次或多次出现\*:表示前面字符的零次或多次出现?:表示前面字符可能出现,也可能不出现- 更为通用的表示出现次数的语法是
{m, n},出现次数从 m 到 n,包括 m 和 n,如果 n 没有限制,可以省略,如果 m 和 n 一样,可以写为{m} - 使用懒惰量词,在量词的后面加一个符号
? - 表达式可以用括号
()括起来,表示一个分组
特殊边界匹配
- 默认情况下,
^匹配整个字符串的开始 - 默认情况下,
$匹配整个字符串的结束 \A与^类似,但不管什么模式,它匹配的总是整个字符串的开始边界。\Z和\z与$类似,但不管什么模式,它们匹配的总是整个字符串的结束边界。\b匹配的是单词边界
环视边界匹配
环视的字面意思就是左右看看,需要左右符合一些条件,本质上,它也是匹配边界,对边界有一些要求,这个要求是针对左边或右边的字符串的。
- 肯定顺序环视,语法是
(? =...),要求右边的字符串匹配指定的表达式。 - 否定顺序环视,语法是
(? ! ...),要求右边的字符串不能匹配指定的表达式。 - 肯定逆序环视,语法是
(? <=...),要求左边的字符串匹配指定的表达式。 - 否定逆序环视,语法是
(? <! ...),要求左边的字符串不能匹配指定的表达式。
这些环视结构也被称为断言,断言的对象是边界,边界不占用字符,没有宽度,所以也被称为零宽度断言。
Java API
正则表达式相关的类位于包 java.util.regex 下,有两个主要的类,一个是 Pattern,另一个是 Matcher
-
表示正则表达式
在 Java 中,没有什么特殊的语法能直接表示正则表达式,需要用字符串表示,而在字符串中,''也是一个元字符,为了在字符串中表示正则表达式的’',就需要使用两个’',即’\',而要匹配’'本身,就需要 4 个’',即’\\’
三种匹配模式:单行模式(点号模式)、多行模式和大小写无关模式,它们对应的常量分别为:Pattern.DOTALL、Pattern.MULTILINE 和 Pattern.CASE_INSENSI-TIVE,多个模式可以一起使用,通过'|'连起来即可
-
切分
-
验证
-
查找
-
替换
List 集合
集合操作最常用的两种方法:add(),iterator()
public interface List<E> extends Collection<E>
Collection 的继承关系,如图:
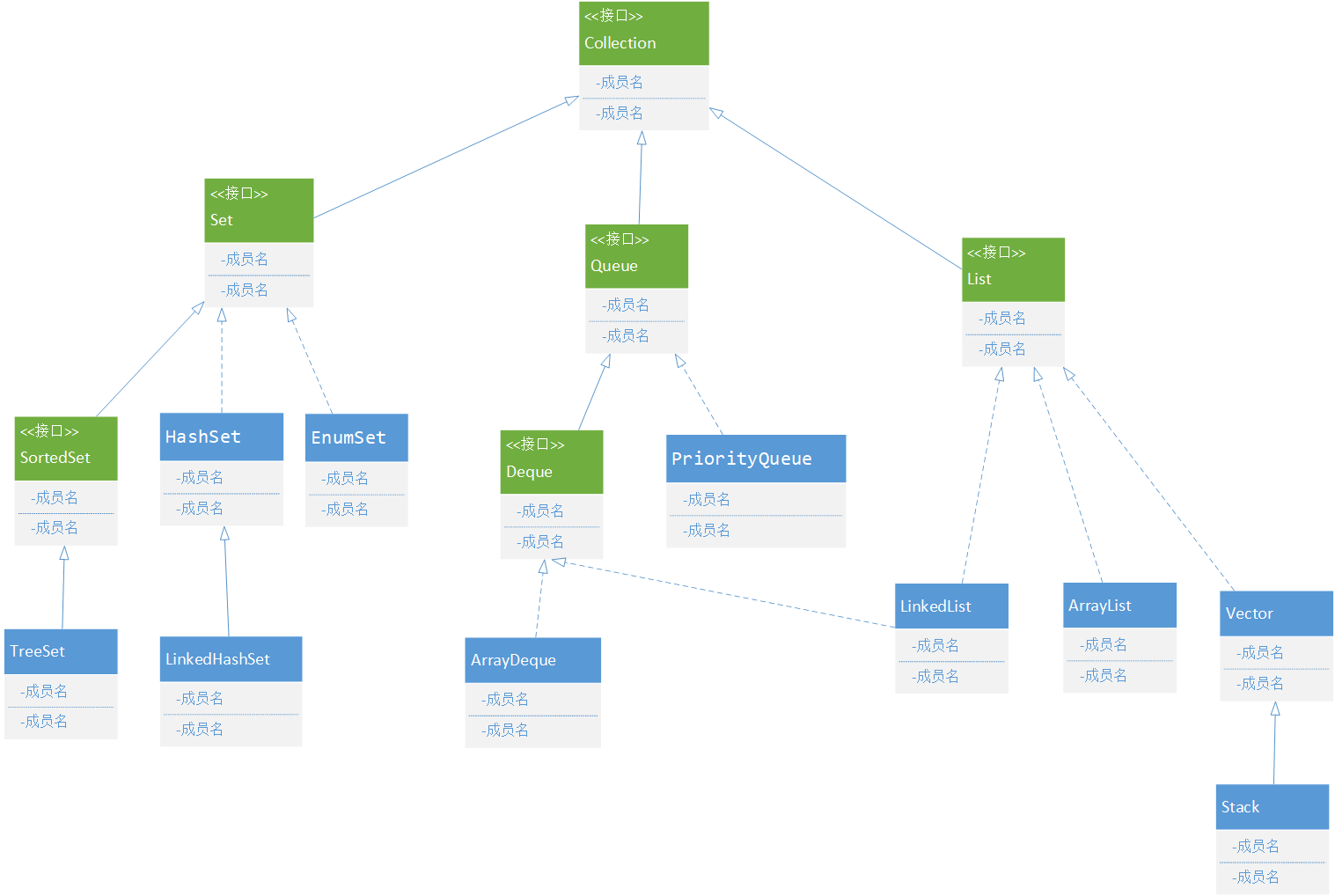
List 的三个常用子类:
ArrayListLinkedListVector
ArrayList
继承关系
|
|
LinkedList
继承关系
|
|
Vector
Vector 是一个古老的集合(从 JDK 1.0 就有了)
继承关系
|
|
Set 集合
Set 集合不允许包含相同的元素,如果试图把两个相同的元素加入同一个 Set 集合中,则添加操作失败,add 方法返回 false,且新元素不会被加入。
Set 判断两个对象相同不是使用==运算符,而是根据 equals 方法
HashSet
HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取和查找性能。
HashSet 不是同步的,如果多个线程同时访问一个 HashSet,假设有两个或者两个以上线程同时修改了 HashSet 集合时,则必须通过代码来保证其同步。
LinkedHashSet
HashSet 还有一个子类 LinkedHashSet,LinkedHashSet 集合也是根据元素的 hashCode 值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。
TreeSet
TreeSet 是 SortedSet 接口的实现类,正如 SortedSet 名字所暗示的,TreeSet 可以确保集合元素处于排序状态。
TreeSet 并不是根据元素的插入顺序进行排序的,而是根据元素实际值的大小来进行排序的。
EnumSet
EnumSet 是一个专为枚举类设计的集合类,EnumSet 中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建 EnumSet 时显式或隐式地指定。EnumSet 的集合元素也是有序的,EnumSet 以枚举值在 Enum 类内的定义顺序来决定集合元素的顺序。
Map 集合
Map 用于保存具有映射关系的数据,因此 Map 集合里保存着两组值,一组值用于保存 Map 里的 key,另外一组值用于保存 Map 里的 value,key 和 value 都可以是任何引用类型的数据。
Map 的继承关系,如图:
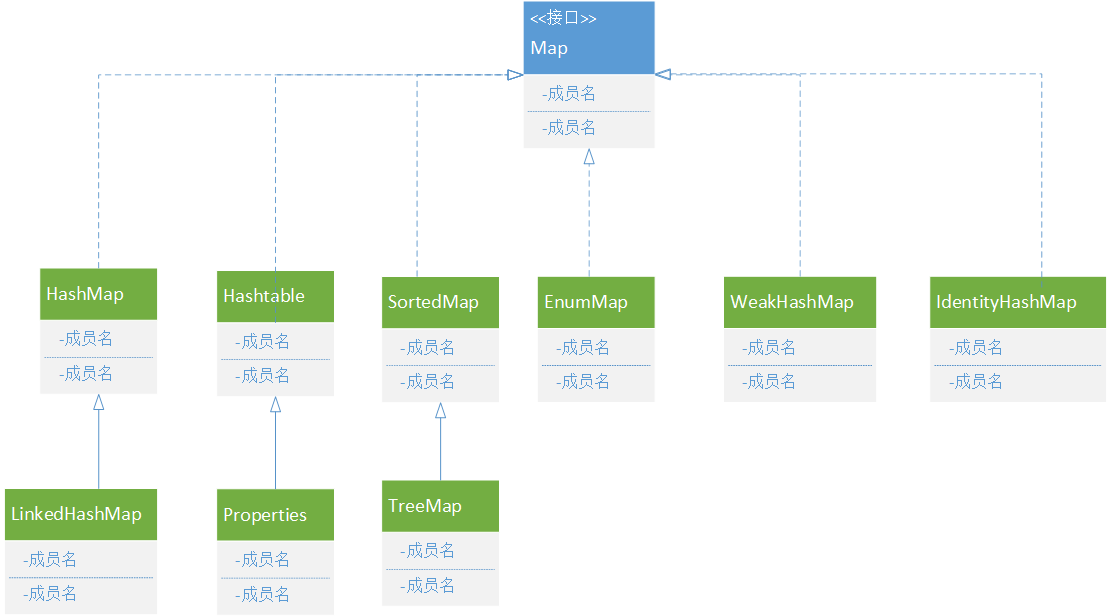
HashMap和Hashtable都是 Map 接口的典型实现类,它们之间的关系完全类似于ArrayList和Vector的关系
Hashtable 是一个线程安全的 Map 实现,但 HashMap 是线程不安全的实现
Hashtable 不允许使用 null 作为 key 和 value
HashMap、Hashtable也不能保证其中 key-value 对的顺序。
Properties类是Hashtable类的子类,正如它的名字所暗示的,该对象在处理属性文件时特别方便(Windows 操作平台上的 ini 文件就是一种属性文件)。
TreeMap就是一个红黑树数据结构,每个 key-value 对即作为红黑树的一个节点。TreeMap存储 key-value 对(节点)时,需要根据 key 对节点进行排序。
ArrayList 和 Vector 的显著区别:ArrayList 是线程不安全的,当多个线程访问同一个 ArrayList 集合时,如果有超过一个线程修改了 ArrayList 集合,则程序必须手动保证该集合的同步性;但 Vector 集合则是线程安全的,无须程序保证该集合的同步性。
Java 多线程编程
Java 是多线程的编程语言,有利于并发访问处理。
继承Thread 类实现多线程
多线程的执行的方法在run()中定义,
start()方法是并发执行
每一个线程类对象只允许启动一次,如果重复启动,就会抛出异常
Runnable接口的使用
|
|
Thread 与 Runnable 关系
Thread 用于实现 Runnable,如图所示:
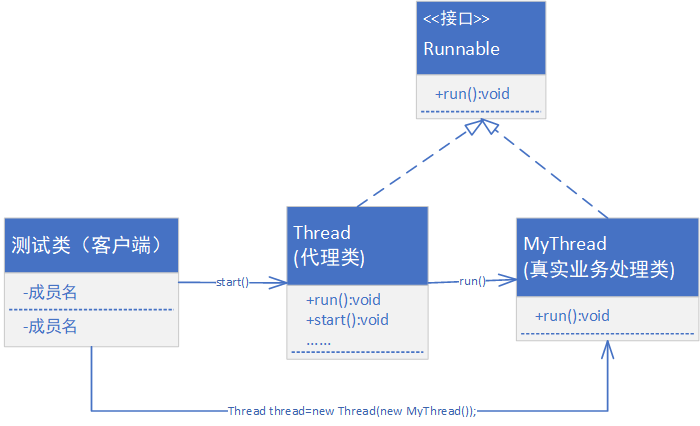
多线程的设计之中,使用了代理设计模式的结构,用户设计的线程主体负责项目核心功能,其他辅助功能由 Thread 类实现
多线程开发的本质实质上是在于多个线程可以进行统一资源的抢占
Callable 实现多线程
Callable的定义
|
|
如图 Callable 的继承关系:
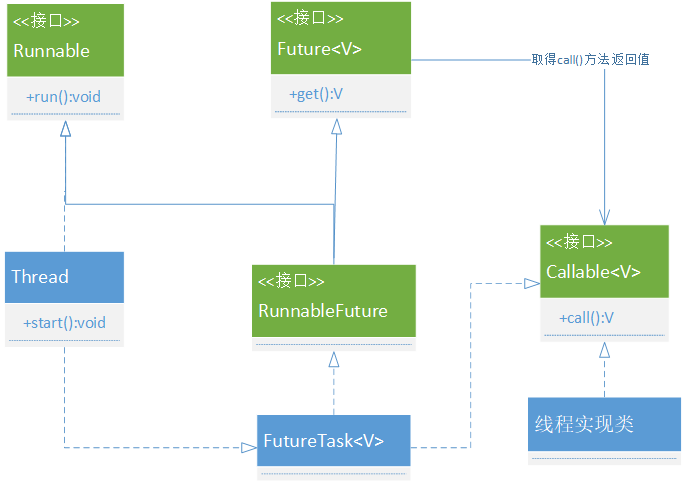
| Runnable | Callable |
|---|---|
| JDK1.0 | JDK1.5 |
| 只有 void run(),无返回值 | V call(),有返回值 |
线程常用操作方法
构造方法public Thread(Runnable target, String name)
设置名字public final synchronized void setName(String name)
取得名字public final String getName()
使用 Java 命令就会启动一个 JVM 的进程,一台电脑可以同时启动若干个 JVM 进程
主线程可以创建若干个子线程,主线程负责处理整体流程,而子线程负责处理耗时操作
线程休眠
两种休眠处理方式
一个参数,毫秒:public static native void sleep(long millis) throws InterruptedException;
两个参数,毫秒纳秒public static void sleep(long millis, int nanos)throws InterruptedException
休眠的主要特点是自动实现线程的唤醒,以继续进行后续的处理,多个线程休眠是有顺序的
线程中断
所有的线程都能被中断,线程中断必须进行异常处理
线程的强制执行
正常情况下主线程和子线程交替执行
强制执行public final void join() throws InterruptedException
线程礼让
礼让方法:public static native void yield();
线程优先级
设置优先级public final void setPriority(int newPriority)
获取优先级public final int getPriority()
三个优先级常量
|
|
优先级高的最有可能先执行,并不是绝对先执行
线程的同步与死锁
同步问题的引出
系统休眠或网络延迟会产生数据不同步问题
线程同步
解决同步问题的关键是锁
关键字synchronized
同步实际上会使系统的性能降低
解决同步问题的两种方法:同步代码块和同步方法
线程死锁
线程死锁就是若干个线程互相等待的状态
死锁是开发中不确定的状态
若干个线程访问同一资源时一定要进行同步处理,而过多的同步则会造成死锁
基础类库
StringBuffer 类
构造方法:public StringBuffer()
构造方法:public StringBuffer(String str)
基本操作方法:
|
|
字符串反转:sb.reverse()
StringBuffer属于线程安全的全部使用synchronized,StringBuilder是非线程安全的。
CharSequence 接口
CharSequence 是描述字符串结构的接口
| String | StringBuffer | StringBuilder |
|---|---|---|
| public final class String extends Object implements Serializable, Comparable |
public final class StringBuffer extends Object implements Serializable, CharSequence |
public final class StringBuilder extends Object implements Serializable, CharSequence |
Runtime 类
在每一个 JVM 只允许提供有一个 Runtime 类的对象,所以这个类的构造方法被默认私有化了
System 类
-
数组拷贝:
public static native void arraycopy(Object src,int srcPos,Object dest,int destPos,int length); -
获取当前日期时间数值:
public static native long currentTimeMillis(); -
进行垃圾回收:
public static void gc()
Math 类
Math 类的全部方法:
|
|
Random 类
生成不包含边界的随机正整数:public int nextInt(int bound)
UUID 类
UUID 是一种生成无重复字符串的一种程序类,这种程序类的主要功能是根据时间戳实现一个自动的无重复字符串定义。
随机获取 UUID:public static UUID randomUUID()
根据字符串获取 UUID 内容:public static UUID fromString(String name)
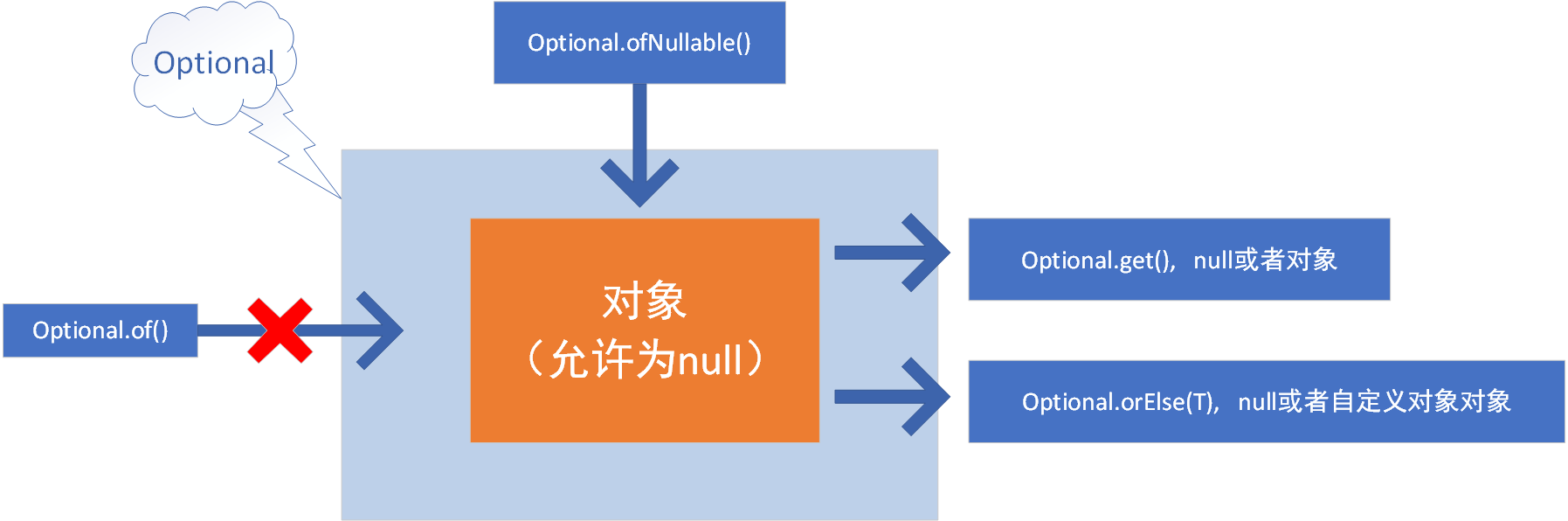
Option 类
Option 类的主要功能是进行 null 的相关处理
返回空数据:public static<T> Optional<T> empty()
获取数据:public T get()
保存数据,但是不许出现 null:public static <T> Optional<T> of(T value)
保存数据,允许出现 null:public static <T> Optional<T> ofNullable(T value)
空的时候返回其他数据:public T orElse(T other)
ThreadLocal 类
构造方法:public ThreadLocal()
设置数据:public void set(T value)
取出数据:public T get()
删除数据:public void remove()
Base64 类
Base64 可以实现加密与解密的处理,包含的内部类和方法如下图:
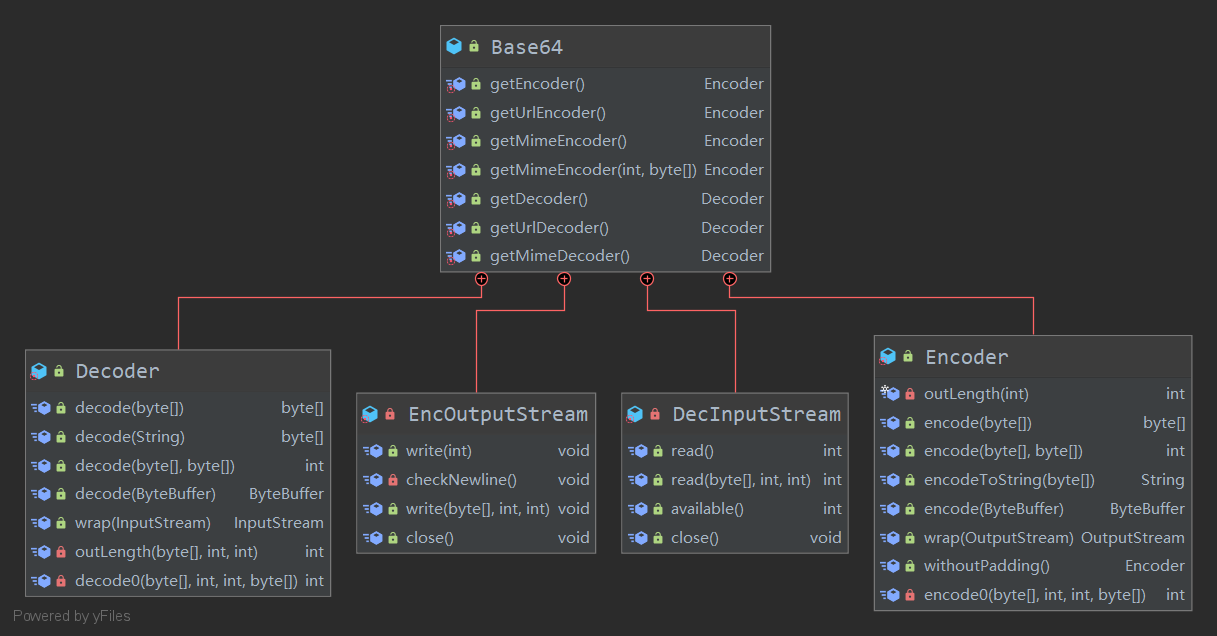
比较器
Arrays 类
数组的排序:public static void sort(int[] a)
数组的输出:public static String toString(int[] a)
Comparable 比较器
接口定义:public interface Comparable<T>
实现比较的方法:int compareTo(T o)
Comparator 比较器
Comparator 属于一种挽救的比较器支持,其主要目的是解决一些没有使用 Comparable 排序的类的对象的数组排序操作
红黑树原理
红黑树(Red Black Tree) 是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。
红黑树是在 1972 年由 Rudolf Bayer 发明的,当时被称为平衡二叉 B 树(symmetric binary B-trees)。后来,在 1978 年被 Leo J. Guibas 和 Robert Sedgewick 修改为如今的“红黑树”。
红黑树是一种特化的 AVL 树(平衡二叉树),都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
它虽然是复杂的,但它的最坏情况运行时间也是非常良好的,并且在实践中是高效的: 它可以在 O(log n)时间内做查找,插入和删除,这里的 n 是树中元素的数目。
红黑树的特点:
- 每个节点不是黑色就是红色
- 根节点必须是黑色
- 叶子节点是黑色
- Java 实现的红黑树使用 null 代表空节点,因此遍历红黑树时将看不到黑丝的叶子节点,反而看到每个叶子节点都是红色的
- 红色节点的子节点必须是黑色的
- 一个节点到该节点的所有子孙节点的所有路径上包含相同数目的黑色节点
利用红色节点与黑色节点实现均衡的控制
文件操作
File 类
构造方法:public File(String pathname)
构造方法:public File(String parent, String child)
创建文件:public boolean createNewFile() throws IOException
判断文件是否存在:public boolean exists()
删除文件:public boolean delete()
Windows 的路径分隔符是\,Linux 的路径分隔符是/,
File 类中的路径分隔符常量separator
获取父路径:public File getParentFile()
创建单级目录:public boolean mkdir()
创建多级目录:public boolean mkdirs()
是否可读:public boolean canRead()
是否可写:public boolean canWrite()
获取文件长度:public long length()
最后得到修改时间:public long lastModified()
判断是否为目录:public boolean isFile()
判断是否为文件:public boolean isDirectory()
列出目录:public File[] listFiles()
字节流与字符流
File 类只能够操作文件本身,而不能操作文件的内容
字节处理流:OutputStream(输出字节流),InputStream(输入字节流)
字符处理流:Writer(输出字符流),Reader(输入字符流)
流的操作属于资源操作,资源操作必须进行关闭处理
OutputStream字节输出流
定义:public abstract class OutputStream implements Closeable, Flushable
OutputStream的继承关系如图:
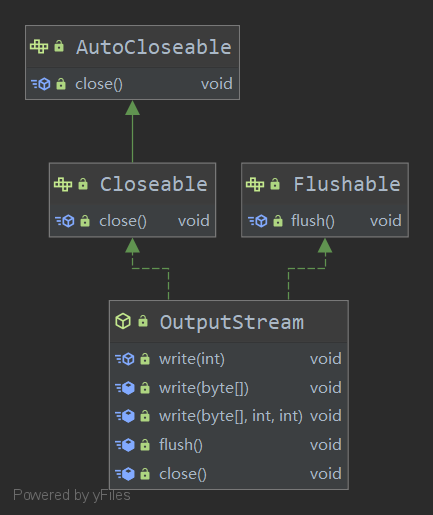
OutputStream是一个公共的输出操作标准
FileOutputStream是OutputStream的实现子类
【覆盖】构造方法:public FileOutputStream(File file) throws FileNotFoundException
【追加】构造方法:public FileOutputStream(File file, boolean append) throws FileNotFoundException
InputStream字节输入流
InputStream的继承关系与方法
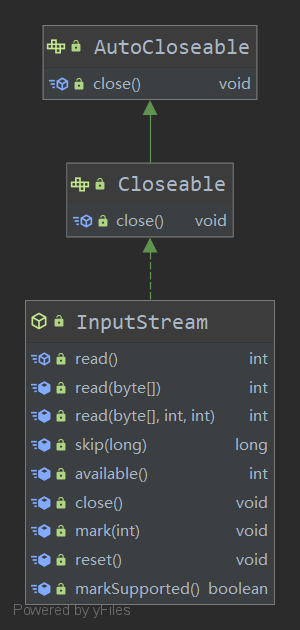
使用 read()方法读取的时候只能够以字节数组为主进行接收
Writer字符输出流
Writer 的继承关系及方法:
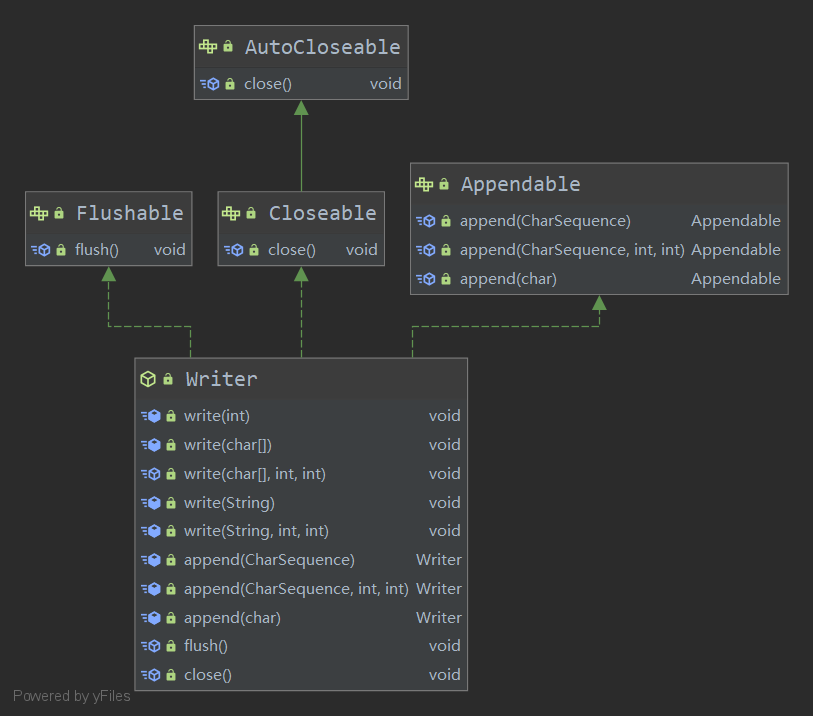
Writer是字符流,字符处理的优势在于中文数据。
Reader字符输入流
Reader 的构造:
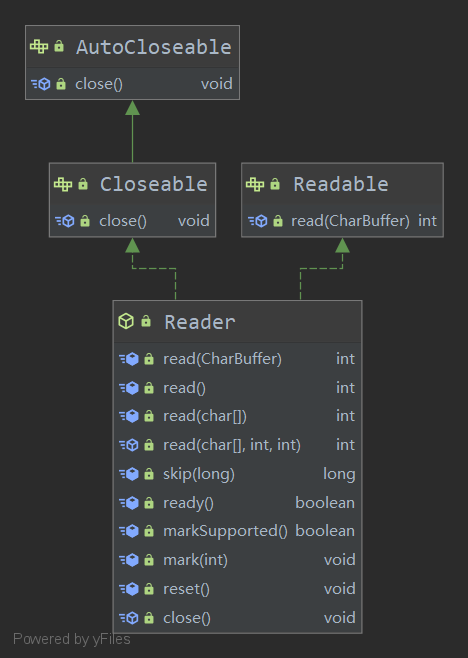
字节流与字符流的区别
OutputStream不关闭可以正常保存
Writer不关闭不能正常保存
因为Writer使用了缓冲区
涉及中文信息的都采用字符流
转换流
OutputStreamWriter |
InputStreamReader |
|---|---|
public class OutputStreamWriter extends Writer |
public class InputStreamReader extends Reader |
public OutputStreamWriter(OutputStream out) |
public InputStreamReader(InputStream in) |
转换流可以使字节流转换为字符流
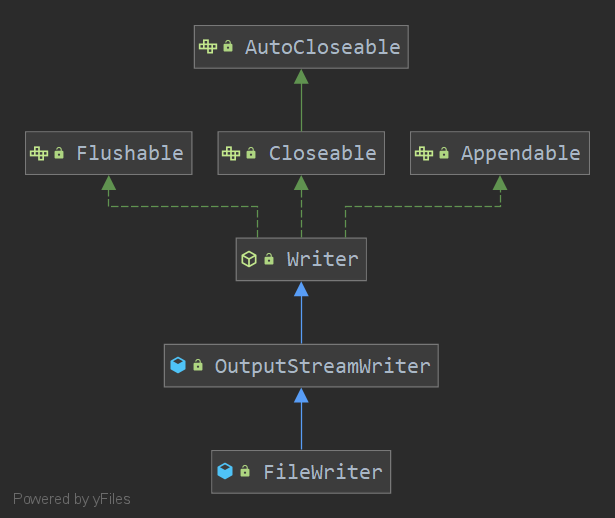
FileWriter继承结构
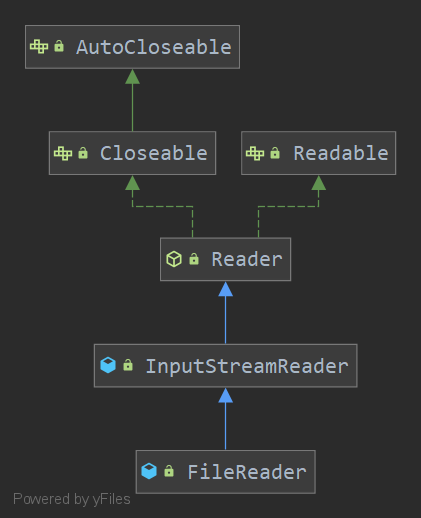
FileReader继承结构
IO 操作深入
字符编码
- GBK/GB2312:国际编码,可以描述中文信息,GB2312 只描述简体中文
- ISO8859-1:国际通用编码,可以用于描述所有字母信息
- UNICODE 编码:采用十六进制方式存储,可用于描述所有的文字信息
- UTF 编码:象形文字采用十六进制编码,字母采用 ISO8859-1 编码,有利于数据传输,节省带宽
- 项目中一般都统一使用 UTF-8 编码
列出系统信息System.getProperties().list(System.out);
内存操作流
Java 有两类内存操作流:
-
字节内存操作流
-
字符内存操作流
管道流
- 字节管道流
- 字符管道流

输入与输出支持
打印流
| PrintStream | PrintWriter |
|---|---|
public class PrintStream extends FilterOutputStream implements Appendable, Closeable |
public class PrintWriter extends Writer |
public PrintStream(OutputStream out) |
public PrintWriter (Writer out),public PrintWriter(OutputStream out) |
对文件进行操作时通常使用打印流
System 类对 IO 的支持
- 标准输出(显示器):
public final static PrintStream out = null; - 错误输出:
public final static PrintStream err = null; - 标准输入(键盘):
public final static InputStream in = null;
|
|
System.out输出黑色字体
System.err输出红色字体
System.in并不常用
BufferedReader缓冲输入流
读取一行数据public String readLine() throws IOException
Scanner 扫描流
构造:public Scanner(InputStream source)
判断是否有数据:public boolean hasNext()
取出数据:public String next()
设置分隔符:public Scanner useDelimiter(Pattern pattern)
对象序列化
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
Person 类产生的每一个对象都可以实现二进制的数据传输,属于可以被序列化的程序类
序列化与反序列化
| 序列化 | 反序列化 |
|---|---|
ObjectOutputStream |
ObjectInputStream |
public class ObjectOutputStream extends OutputStream implements ObjectOutput, ObjectStreamConstants |
public class ObjectInputStream extends InputStream implements ObjectInput, ObjectStreamConstants |
public ObjectOutputStream(OutputStream out) throws IOException |
public ObjectInputStream(InputStream in) throws IOException |
public final void writeObject(Object obj) throws IOException |
public final Object readObject() throws IOException, ClassNotFoundException |
在 Java 中的序列化与反序列化必须使用内部提供的对象操作流,如果要实现一组对象的序列化,则可以使用对象数组完成
transient 关键字
默认情况下当执行了对象序列化的时候会将类中的全部属性的内容进行全部的序列化操作,但是很多情况下有一些属性可能并不需要进行序列化的处理。
private transient String name;
进行序列化处理的时候,name属性的内容是不会被保存下来的,换言之,读取的数据name将是其对应数据类型的默认值null
反射机制
所有的技术实现的目标只有一点:重用性
根据实例化对象反推出其类型
- 获取 Class 对象信息:
public final Class<?> getClass()- class 类定义:
public final class Class<T> implements java.io.Serializable,GenericDeclaration,Type,AnnotatedElement
- class 类定义:
- JVM 直接支持采用“类.class”的形式实例化
- Class.forName().
public static Class<?> forName(String className) throws ClassNotFoundException
反射实例化对象
通过public T newInstance()实例化对象
相当于“类名 对象名 = new 类()”,但是该方法只能调用无参构造,JDK9 之后被废弃
集合工具类
Stack 类
入栈public E push(E item)
出栈public synchronized E pop()
Stack 的继承结构如下:
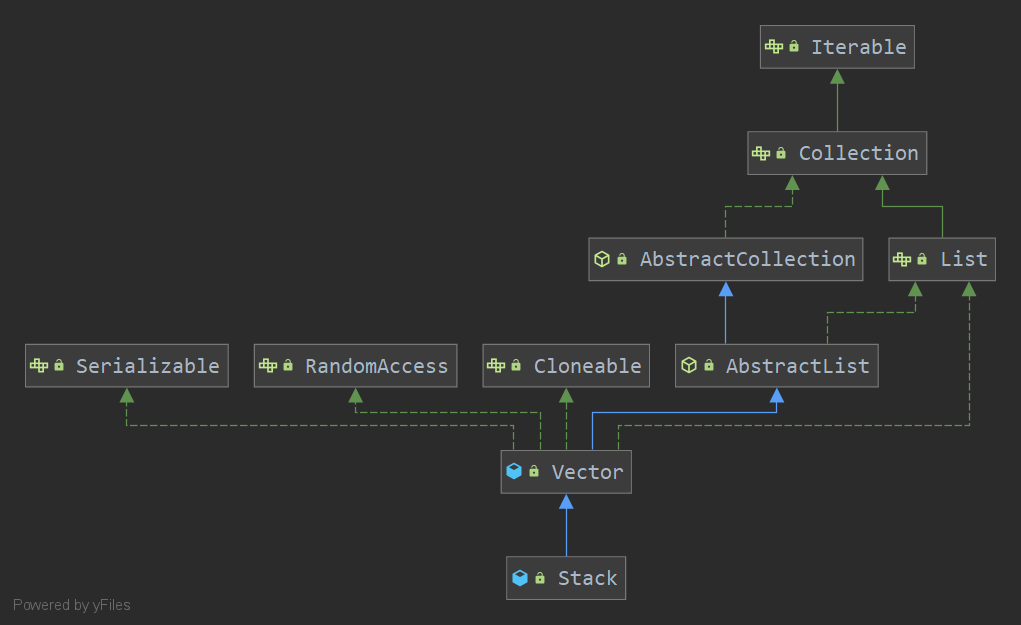
空栈时出栈会出现Exception in thread "main" java.util.EmptyStackException
Queue 接口
追加数据:boolean add(E e);或boolean offer(E e);
通过队列获取数据:E poll();弹出后删除数据
优先级队列PriorityQueue
Properties 属性操作
Properties 类只能操作 String
使用 Properties 类型的最大特点是可以进行资源内容的输入与输出的处理操作
Collections 类
解释 Collection 与 Collections 的区别
- Collection 是集合接口,允许保存单值对象
- Collections 是集合操作的工具类。
Stream 数据流
Stream 基础操作
Stream 主要功能是进行数据的分析处理,主要是针对于集合中的数据进行分析操作
可以通过函数式编程进行数据的流式处理
数据采集
<R, A> R collect(Collector<? super T, A, R> collector);
分页处理方法
-
设置取出的最大数据量:
Stream<T> limit(long maxSize); -
跳过指定数据量:
Stream<T> skip(long n);
MapReduce 基础模型
all.stream()用于初始化 Stream 对象
.filter((ele)->ele.getName().contains("小米"))过滤出商品名称中含有小米的数据。
.mapToDouble((olderObject)->olderObject.getPrice()*olderObject.getCount()).summaryStatistics();计算出单种商品的总价,然后返回DoubleSummaryStatistics类型的对象。
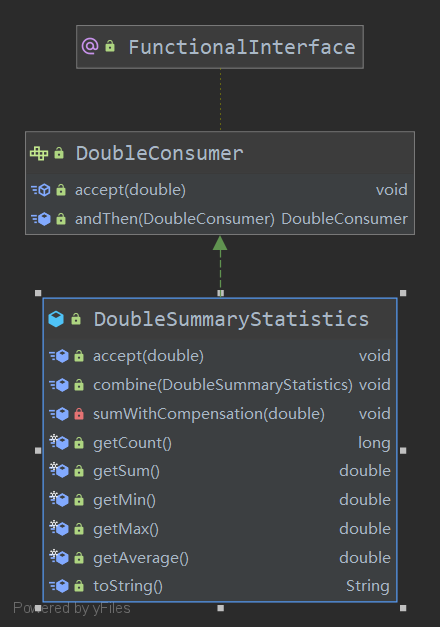
DoubleSummaryStatistics一些常用的方法
网络编程
针对网络程序的开发有两种模型:
- C/S(Client/Server,客户端与服务器端)
- B/S(Browser/Server,浏览器与服务器端)
TCP(可靠的数据连接)
UDP(不可靠的数据连接)
TCP
TCP 的程序开发是网络程序最基本的开发模型,其核心的特点是使用两个类实现数据的交互处理:ServerSocket(服务器端),Socket(客户端)
简要工作流程如图:
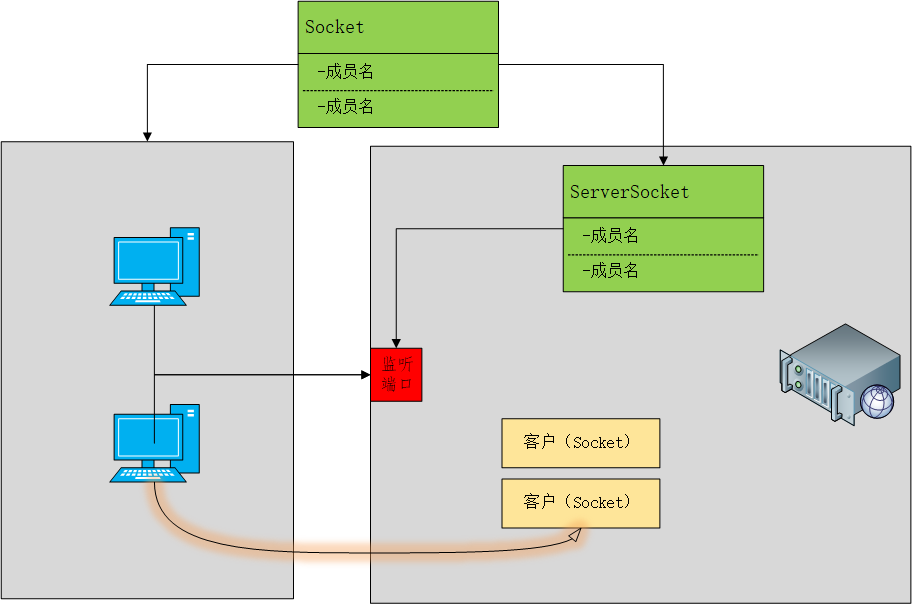
ServerSocket 的主要目的是设置服务器监听的端口,Socket 要指明要连接的服务器地址与端口
UDP
UDP 程序是基于数据报的网络编程实现,如果想实现 UDP 程序需要两个类:DatagramSocket和DatagramPacket
JDBC
对于 JDBC 的程序数据库的访问分为如下四种形式:
-
JDBC-ODBC 桥连接
处理流程:程序 →JDBC→ODBC→ 数据库
-
JDBC 连接:直接通过 JDBC 进行数据库的连接
处理流程:程序 →JDBC→ 数据库
-
JDBC 网络连接:通过特定的网络协议连接指定的数据库服务
处理流程:程序 →JDBC→ 网络数据库(IP 地址,端口号)
-
JDBC 协议连接
Java 访问 MySQL 过程;
-
设置驱动
1`static final String JDBC_DRIVER = "com.mysql.jdbc.Driver"; -
设置数据库地址
1static final String DB_URL = "jdbc:mysql://localhost:3308/test"; -
设置用户名和密码
1 2static final String USER = "root"; static final String PASS = "123456"; -
初始化连接对象和游标对象
1 2Connection conn = null; Statement stmt = null; -
注册 JDBC 驱动
1Class.forName(JDBC_DRIVER); -
打开连接
1conn = DriverManager.getConnection(DB_URL, USER, PASS); -
执行查询语句
1 2 3 4 5System.out.println(" 实例化Statement对象..."); stmt = conn.createStatement(); String sql; sql = "SELECT id, name, url FROM websites"; ResultSet rs = stmt.executeQuery(sql); -
用
ResultSet对象接收返回结果1ResultSet rs = stmt.executeQuery(sql); -
遍历
ResultSet对象1 2 3 4 5 6 7 8 9 10 11while (rs.next()) { // 通过字段检索 int id = rs.getInt("id"); String name = rs.getString("name"); String url = rs.getString("url"); // 输出数据 System.out.print("ID: " + id); System.out.print(", 站点名称: " + name); System.out.print(", 站点 URL: " + url); System.out.print("\n"); } -
关闭资源
|
|
运行结果:
|
|
MySQL 8.0 以上版本需设置 JDBC 为
static final String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver";

